
Notice
Recent Posts
Recent Comments
Link
Susan and Data
파이썬(판다스)_결측값을 채워보자! 본문
결측값
[함수]
1. df.info: 열 타입 및 결측값 갯수 확인 가능
2. mode: 가장 빈번하게 측정되는 값
3. fillna: 데이터프레임에서 결측값을 원하는 값으로 변경
* axis: {0:index / 1:columns} / inplace: 원본 변경 여부(True일 경우, 원본 변경)
4. dropna: 데이터프레임 내 결측값이 포함된 레이블을 제거
* axis: {0:index / 1:columns} / how: {'any': 결측치가 존재하면 제거 / 'all': 모두 결측치면 제거}
5. reset_index: 설정 인덱스를 제거하고 기본 인덱스로 변경
6. df.drop: 열 삭제
* axis: {0:index / 1:columns} / inplace: 원본 변경 여부(True일 경우, 원본 변경)
[DataFrame 인덱싱]
| 방법 | 내용 | |
| df[] | df['column'] | 해당 컬럼 인덱싱 |
| df['column', 'column'] | 해당 리스트의 컬럼 인덱싱 | |
| df['row':'row'] | 첫번째 지정한 row부터 마지막으로 지정한 row까지 인덱싱 | |
| df.loc[] | df.loc[:, 'column'] | 모든 row의 해당 컬럼 인덱싱 |
| df.loc[:, ['column', 'column']] | 모든 row의 해당 리스트의 컬럼 인덱싱 | |
| df.loc[:, 'column':'column'] | 모든 row의 첫번째 지정한 column부터 마지막으로 지정한 column까지 인덱싱 | |
| df.iloc[] | df.iloc[인덱스값] | 지정한 인덱스 값에 해당하는 row 및 column 인덱싱 |
| df.iloc[:, column의 인덱스 값] | 모든 row의 해당 컬럼 인덱싱 | |
| df.iloc[:, [column의 인덱스 값, column의 인덱스 값]] | 모든 row의 해당 리스트의 컬럼 인덱싱 | |
| df.iloc[:, column의 인덱스 값:column의 인덱스 값] | 모든 row의 첫번째 지정한 column부터 마지막으로 지정한 column까지 인덱싱 |
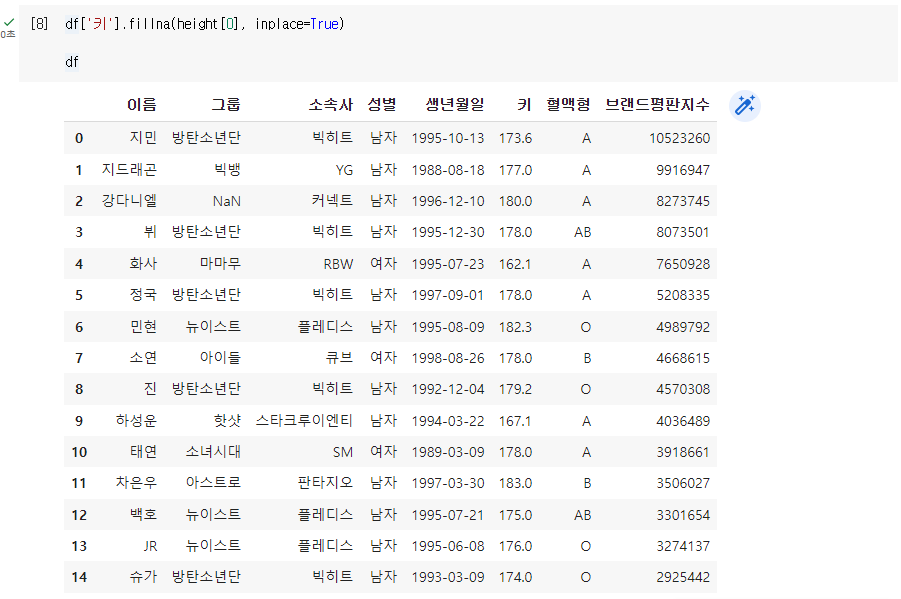
Q. 키의 결측값을 최빈값으로 채우기



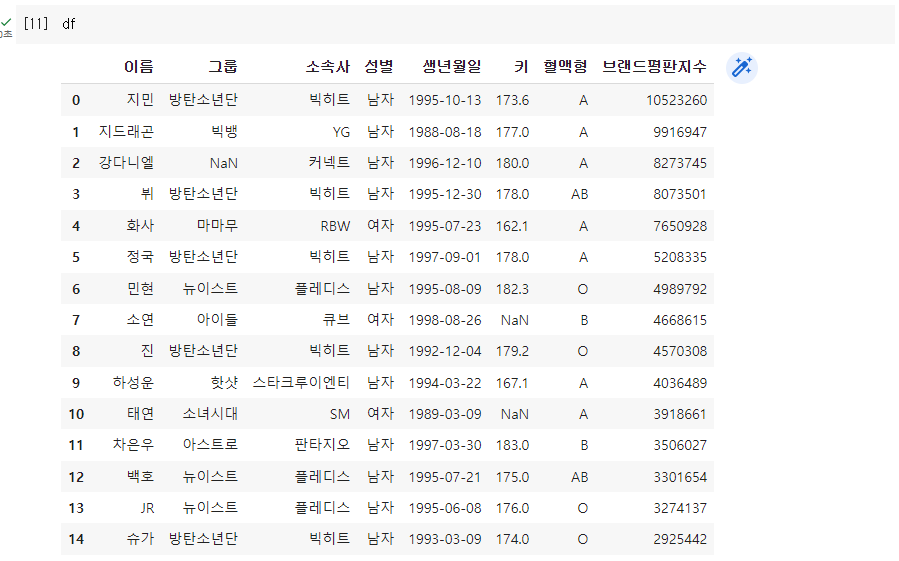
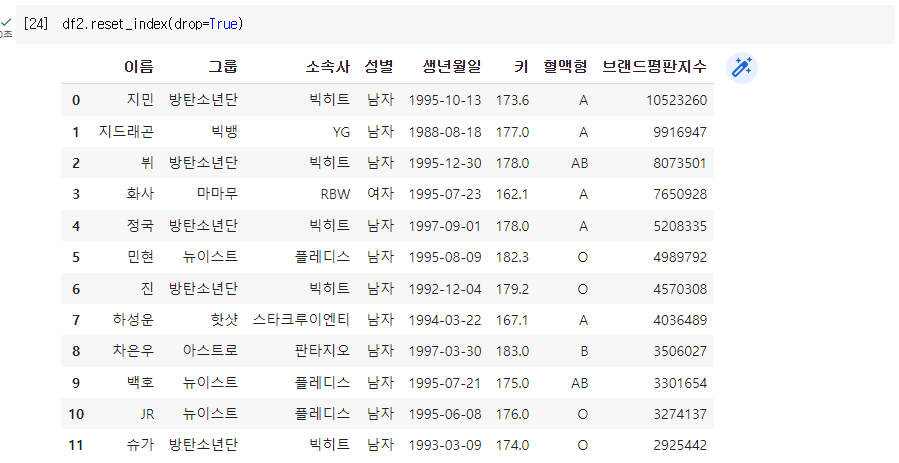
Q. 결측값이 있는 행 제거 후 인덱스를 다시 부여
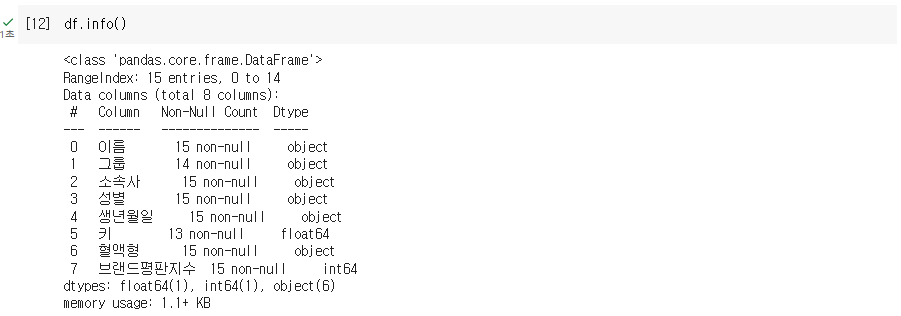
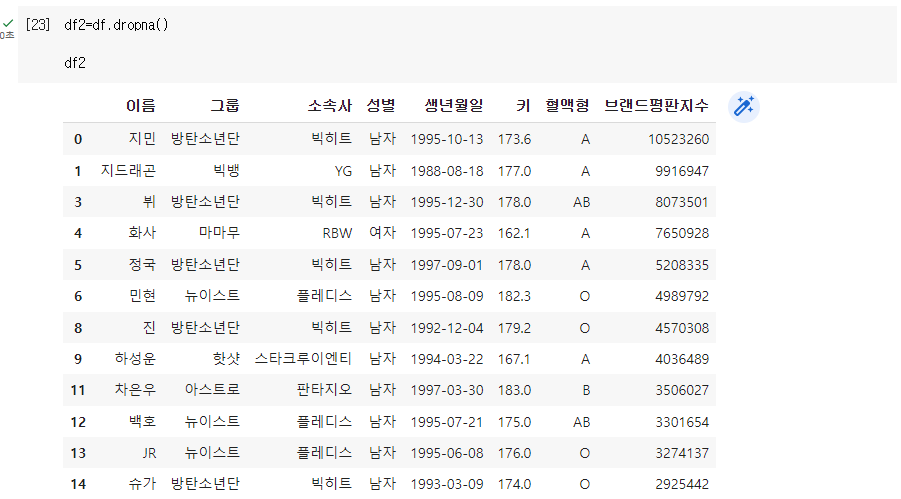
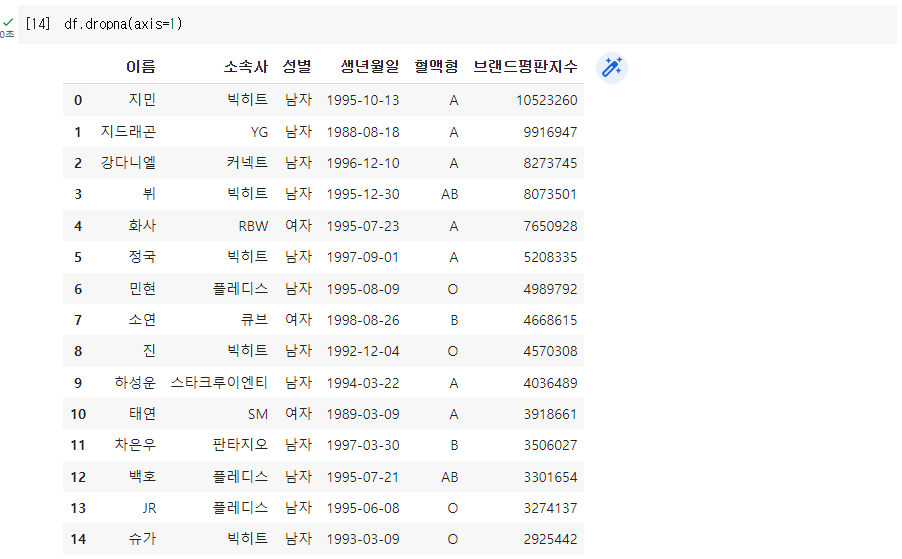
Q. 결측치가 있는 컬럼 삭제
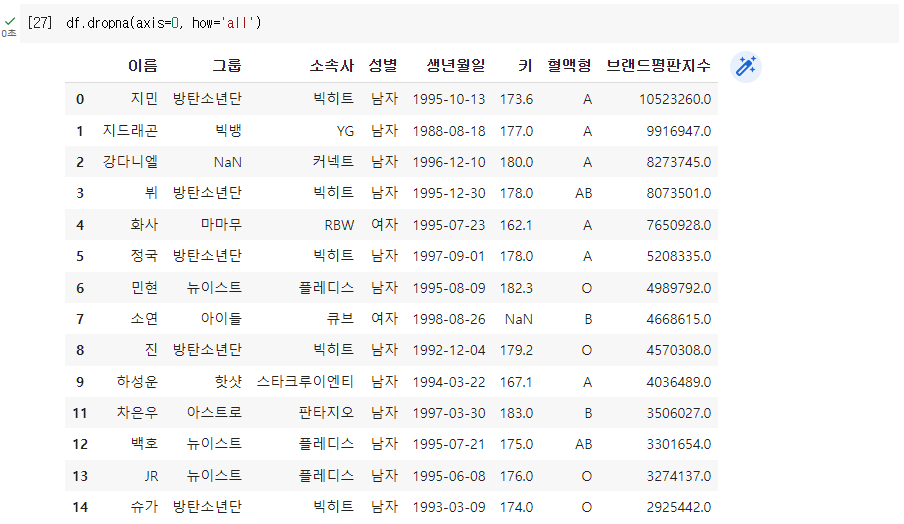
Q. 행 전체가 결측값인 행만 삭제
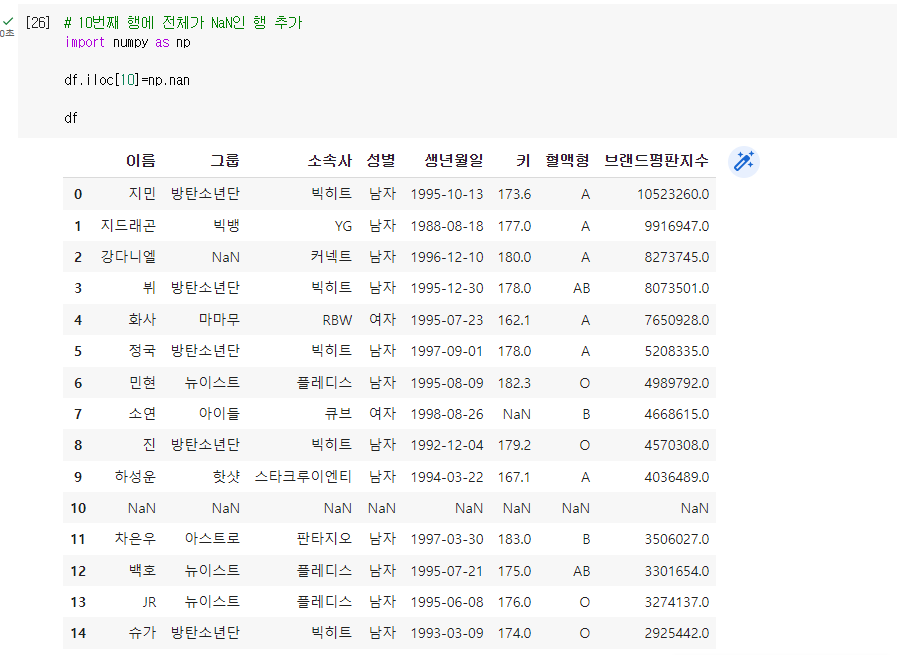
Q. 키와 혈액형 컬럼 제거
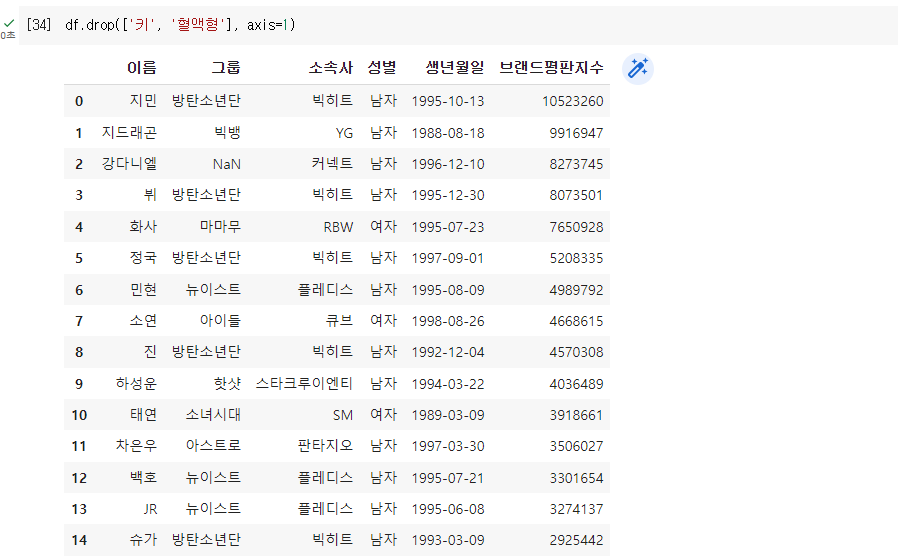
'IT > Python' 카테고리의 다른 글
| 파이썬(판다스)_데이터 타입을 변경해보자! (0) | 2023.04.13 |
|---|---|
| 파이썬(판다스)_concat과 merge를 사용해보자! (0) | 2023.04.12 |
| 파이썬(판다스)_데이터프레임을 복사한 후 변경해보자! (0) | 2023.04.07 |
| 파이썬(판다스)_결측값을 확인해보자! (0) | 2023.04.05 |
| 파이썬(판다스)_info, describe, sort를 사용해보자! (0) | 2023.04.03 |
'IT/Python' Related Articles
more




Comments