
Susan and Data
파이썬(판다스)_데이터프레임을 복사한 후 변경해보자! 본문
2021년 상반기 지역별 배달음식 평균주문금액
[함수]
1. df.copy: 데이터 복사
2. df.info: 열 타입 및 결측값 갯수 확인 가능
3. df.drop: 열 삭제
* axis: {0:index / 1:columns} / inplace: 원본 변경 여부(True일 경우, 원본 변경)
4. min: 최소값을 찾아 리턴
5. max: 최대값을 찾아 리턴
6. sum: 요소들의 합을 리턴
7. mean: 자료의 합을 자료의 갯수로 나눈 값
8. median: 자료를 크기 순으로 정렬했을 때 정 가운데에 있는 값
9. mode: 가장 빈번하게 측정되는 값
10. groupby: 같은 값을 하나로 묶어 통계 또는 집계 결과를 얻기 위해 사용
11. reset_index: 설정 인덱스를 제거하고 기본 인덱스로 변경
[DataFrame 인덱싱]
| 방법 | 내용 | |
| df[] | df['column'] | 해당 컬럼 인덱싱 |
| df['column', 'column'] | 해당 리스트의 컬럼 인덱싱 | |
| df['row':'row'] | 첫번째 지정한 row부터 마지막으로 지정한 row까지 인덱싱 | |
| df.loc[] | df.loc[:, 'column'] | 모든 row의 해당 컬럼 인덱싱 |
| df.loc[:, ['column', 'column']] | 모든 row의 해당 리스트의 컬럼 인덱싱 | |
| df.loc[:, 'column':'column'] | 모든 row의 첫번째 지정한 column부터 마지막으로 지정한 column까지 인덱싱 | |
| df.iloc[] | df.iloc[인덱스값] | 지정한 인덱스 값에 해당하는 row 및 column 인덱싱 |
| df.iloc[:, column의 인덱스 값] | 모든 row의 해당 컬럼 인덱싱 | |
| df.iloc[:, [column의 인덱스 값, column의 인덱스 값]] | 모든 row의 해당 리스트의 컬럼 인덱싱 | |
| df.iloc[:, column의 인덱스 값:column의 인덱스 값] | 모든 row의 첫번째 지정한 column부터 마지막으로 지정한 column까지 인덱싱 |
Q. df를 새로운 변수에 대입하고, 새로운 변수의 시간 컬럼 내용을 전체 0으로 변경



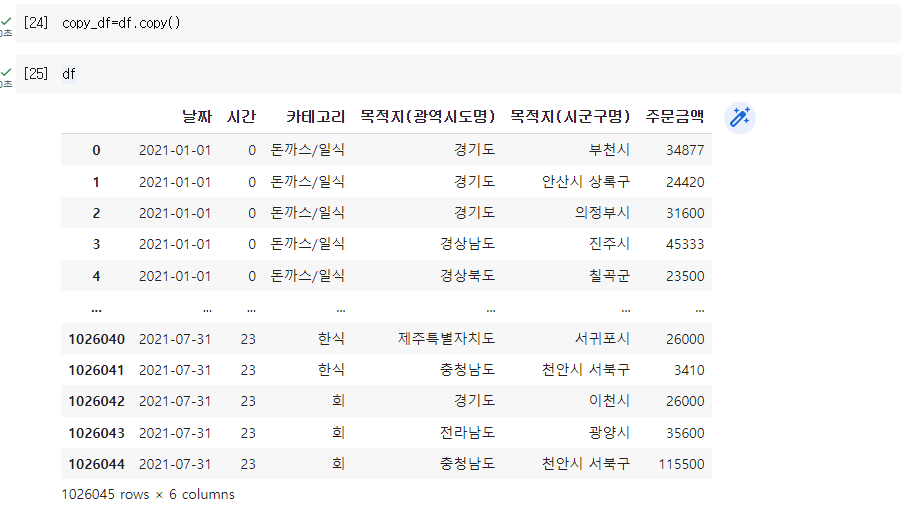
Q. 원본 데이터를 유지하고, 새로운 변수에 복사

Q. 원본 데이터에 2021-07-31 / 23 / 회 / 우리집 / 우리집 / 10000 데이터 추가

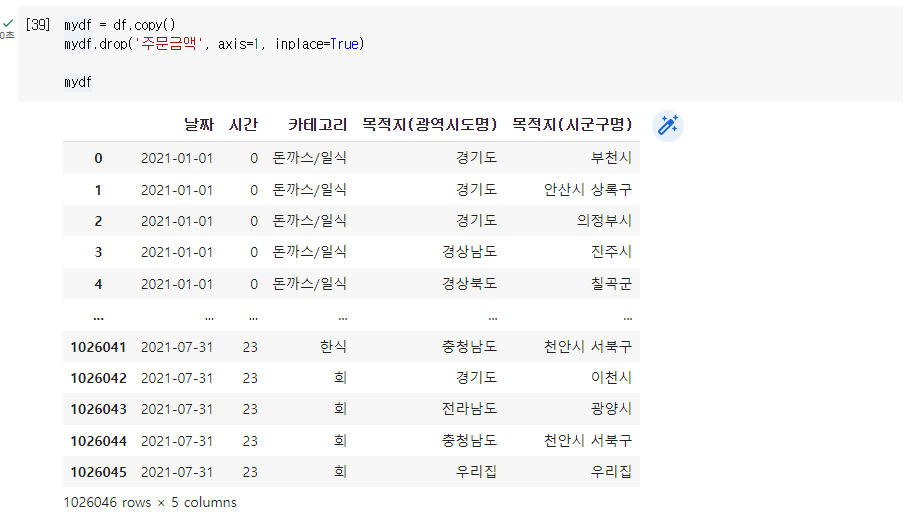
Q. 원본 데이터를 유지하고, 새로운 변수에 복사한 후 시간 컬럼 삭제

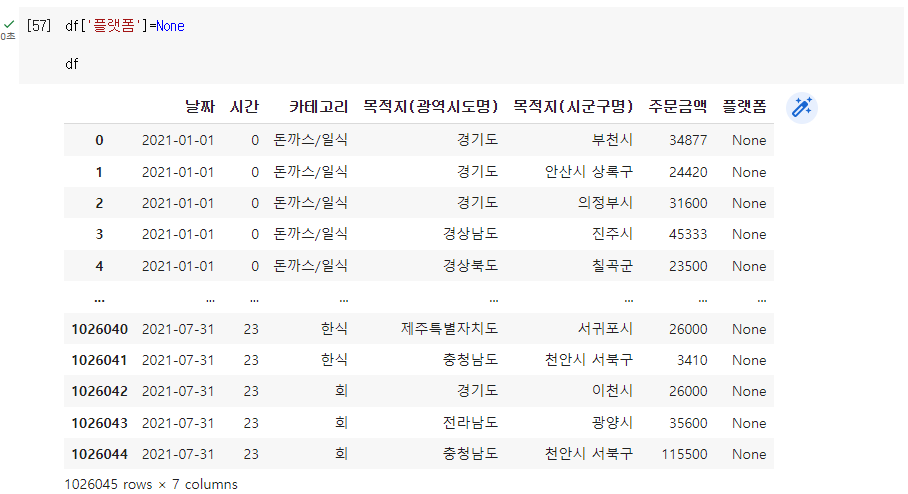
Q. 플랫폼이라는 이름으로 컬럼 추가

Q. 날짜 2021-01-01, 목적지(시군구명) 안산시 상록구, 주문금액 24420인 데이터의 플랫폼을 쿠팡이츠로 변경

Q. 주문금액의 최소값 확인

Q. 주문금액의 최대값 확인

Q. 전체 주문금액 합계 확인

Q. 주문금액 평균 확인

Q. 주문금액의 중앙값 확인

Q. 주문금액의 최빈값 확인

Q. 카테고리별 주문금액 확인

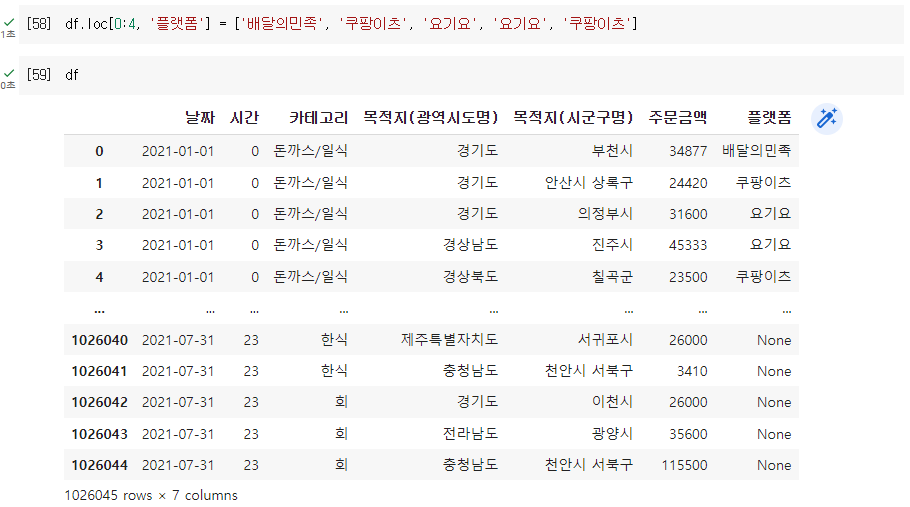
Q. 원본 데이터에 플랫폼 컬럼 추가 후, 0번 부터 4번 컬럼까지 아래의 내용 추가
배달의민족
쿠팡이츠
요기요
요기요
쿠팡이츠
'IT > Python' 카테고리의 다른 글
| 파이썬(판다스)_concat과 merge를 사용해보자! (0) | 2023.04.12 |
|---|---|
| 파이썬(판다스)_결측값을 채워보자! (0) | 2023.04.11 |
| 파이썬(판다스)_결측값을 확인해보자! (0) | 2023.04.05 |
| 파이썬(판다스)_info, describe, sort를 사용해보자! (0) | 2023.04.03 |
| 파이썬(판다스)_데이터프레임을 생성해보자! (0) | 2023.03.26 |



